
De volgende golf van AI zal worden gedefinieerd door agentische systemen die acties kunnen ondernemen: databases doorzoeken, door portalen navigeren, records ophalen en in toenemende mate op grote schaal communiceren met de publieke digitale infrastructuur.
Die verschuiving is nu al merkbaar nu het verkeer dat overheidssites en -diensten bereikt, machineverkeer wordt. Een deel ervan is goedaardig (zoeken en ontdekken). Een deel ervan is dubbelzinnig (scraping en geautomatiseerd browsen). En een deel ervan zou actief schadelijk kunnen worden als agenten schaarse diensten kunnen reserveren, frauduleuze verzoeken kunnen indienen of volumes kunnen genereren die publieke systemen overweldigen.
Het probleem is dat de huidige interfaces van de overheid niet zijn ontworpen voor interacties tussen agenten en overheden, en dat de standaardtoestand van de wereld improvisatie is geworden: agenten komen er ‘uit’ door pagina’s te schrappen en te raden op basis van eerder geleerde informatie.
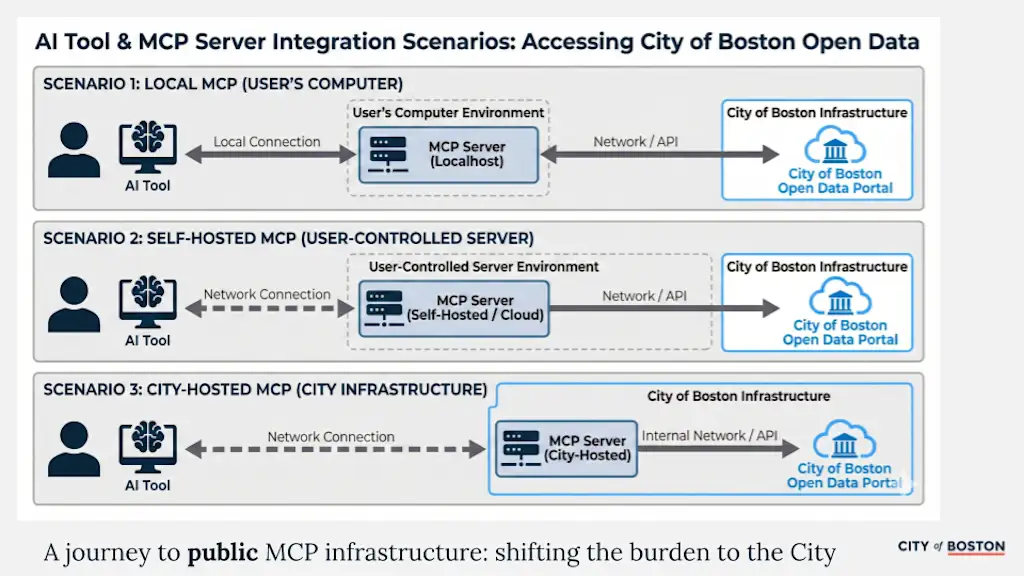
Dit is waar het werk van Boston leerzaam wordt. In plaats van agenten te behandelen als iets dat de groothandel kan blokkeren, of iets dat zonder vangrails moet worden omarmd, experimenteert Boston met een middenweg: het bouwen van een bestuurde, veilige en betrouwbare laag die bemiddelt in de manier waarop AI-agentsystemen omgaan met overheidsbronnen.
In een recent interview zei de CIO van Boston: Sint-Garcesbeschreef waarom de stad investeert in het Model Context Protocol (MCP) als die laag; waarom ze beginnen met open data als proeftuin met een laag risico; hoe ze de betrouwbaarheid verbeteren door berekeningen naar het dataportaal zelf te pushen; en wat er nodig is voordat MCP-achtige infrastructuur een repliceerbare digitale openbare infrastructuur wordt die andere steden kunnen inzetten.
Kun je MCP uitleggen, en waarom stadsbesturen zich daar druk over zouden moeten maken?
MCP staat voor Model Context Protocol en is relatief recent. Anthropic, het bedrijf achter Claude, lanceerde ongeveer een jaar geleden MCP-servers. Waarom het belangrijk is, is dat het grote taalmodellen een manier biedt om te communiceren met het soort middelen dat we bij de overheid hebben. Concreet is het een manier om LLM’s te verbinden met API’s en andere programmatische systemen, waardoor een AI-assistent bijvoorbeeld OV-updates kan ophalen of een serviceverzoek kan indienen via officiële stadssystemen. Wij denken dat het een nieuwe laag wordt die als intermediair fungeert tussen de digitale infrastructuur van de overheid en deze modellen.
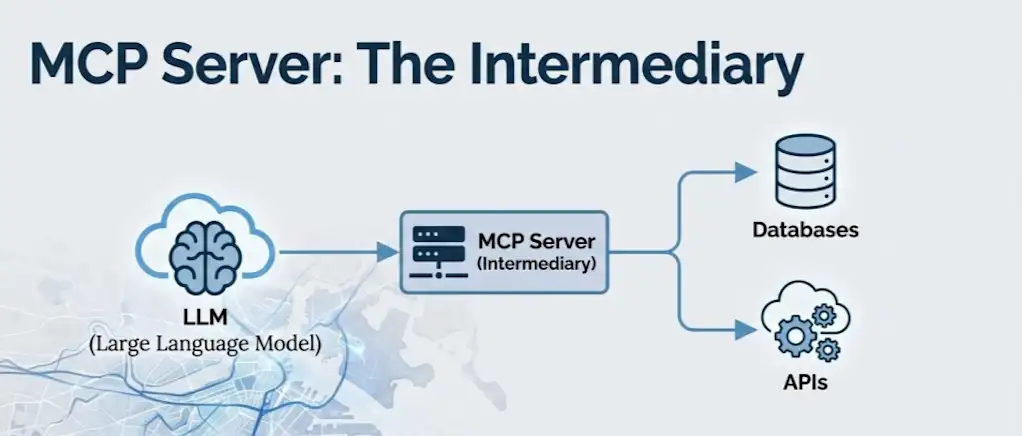
Dit is spannend voor Boston omdat de wereld snel verandert en we nu al zien dat websites en services worden geactiveerd of gebruikt door agenten. MCP-servers kunnen dienen als een laag waarmee de overheid bestuur en controle kan toevoegen.
Mechanisch gezien creëert een MCP-server een reeks tools. Je beschrijft in duidelijke taal wanneer een tool gebruikt moet worden. Vervolgens definieert u welke invoer moet worden geëxtraheerd uit een verzoek in natuurlijke taal en hoe dat zich vertaalt in deterministische programmatische toegang tot een bron. LLM’s kunnen willekeurig zijn; MCP maakt deel uit van het traject om bepaalde interacties betrouwbaarder en veiliger te maken.
De droom is dat steden in deze infrastructuur investeren en verschillende modellen aanwijzen voor interactie met de MCP-laag van een stad, waardoor deze betrouwbaar en veilig is en een betere ervaring biedt voor mensen die agentische systemen gebruiken om met de overheid te communiceren. Er moet veel waar zijn voor die toekomst, maar we zijn er erg enthousiast over.
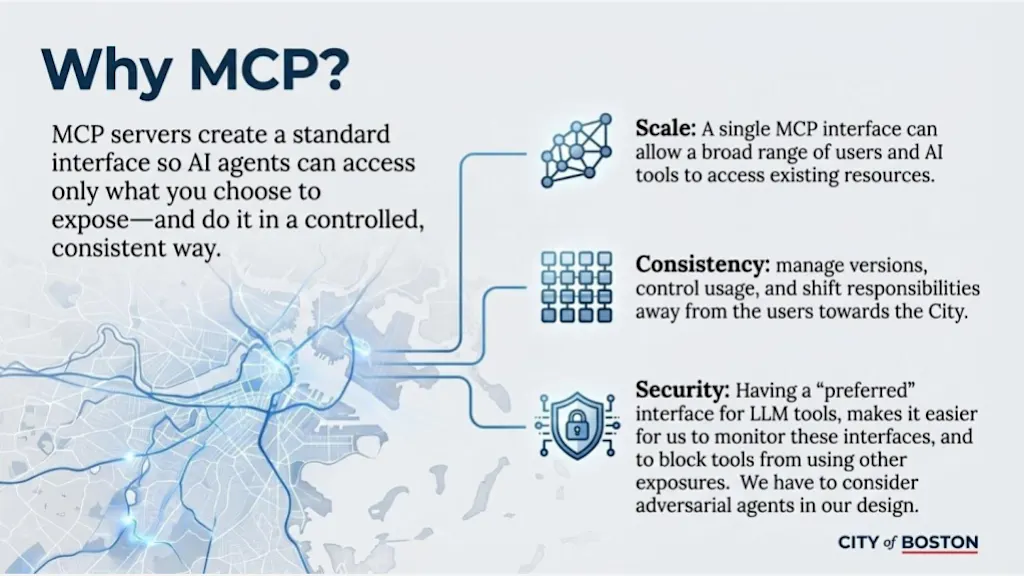
Wat gaat er normaal gesproken kapot als mensen vertrouwen op “alleen de chatbot” en vragen: welk probleem lost MCP op?
Neem onze eerste MCP-server: open data. Als je Claude, ChatGPT of Gemini iets vraagt in de trant van: ‘Hoeveel restaurants zijn er in Boston’, zullen die modellen antwoorden op basis van (1) hun trainingsgegevens, die waarschijnlijk verouderd zijn, of (2) ze zullen iets verzinnen. Het risico op onnauwkeurigheid of hallucinatie is groot.
Het werkt misschien beter als het op internet kan surfen, maar dan vertrouw je erop om de juiste bron te vinden, en we weten dat veel informatie online verouderd of onnauwkeurig is. Het kan afkomstig zijn uit een oud rapport of een artikel van vijf jaar geleden.
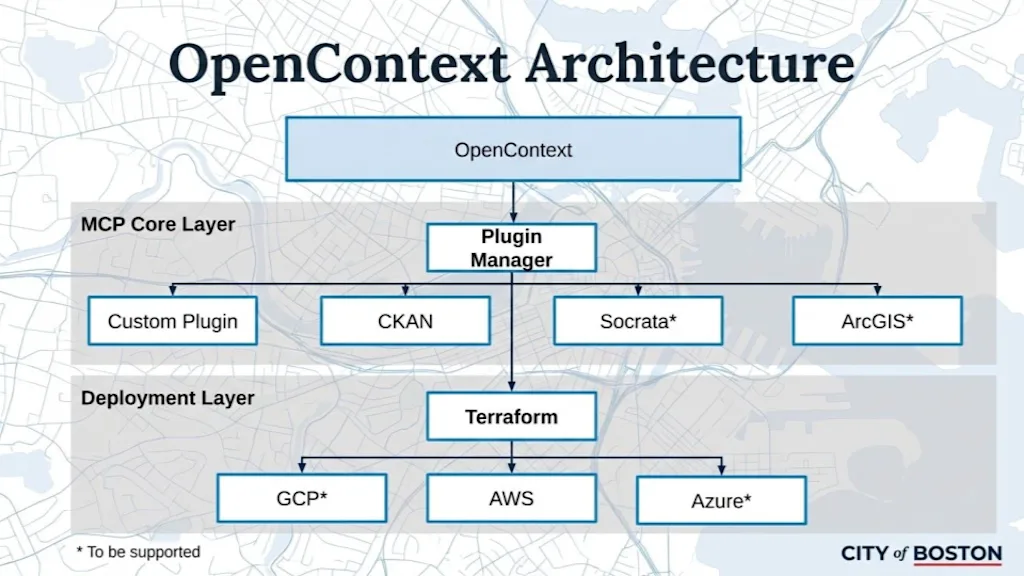
Wat we hebben kunnen doen met Open Context, ons eerste MCP-exemplaar dat is gekoppeld aan het open dataportaal van Boston, is een directe link creëren tussen het portaal en deze AI-tools. MCP-servers zijn interoperabel, dus het maakt niet uit welke AI-tool u gebruikt.
Als je een AI-tool die op deze MCP-server is aangesloten, vraagt: “Hoeveel restaurants zijn er in Boston gezien het open dataportaal”, doorzoekt het automatisch het Boston-portaal, vindt de juiste dataset en genereert een SQL-query op basis van die dataset. Het vraagt op betrouwbare wijze live-gegevens op en retourneert een antwoord dat is gebaseerd op de daadwerkelijke data-infrastructuur van de stad.
We besteden veel geld en tijd aan het bouwen van een data-infrastructuur die veel mensen niet gebruiken omdat het lastig is. De meeste mensen kennen SQL niet, en zelfs weten welke dataset de juiste is, is moeilijk. Deze tools overbruggen die kloof, brengen u tot het juiste antwoord en vermijden veel van de valkuilen in de huidige AI-tools.
Hoe hebben jullie dit betrouwbaarder gemaakt en hoe zag het ontwikkelproces eruit?
We zijn in het najaar van 2025 begonnen met studenten van het AI for Impact-programma van Northeastern in het Burnes Center. We hebben een tool uitgerold voor medewerkers van de stad Boston, genaamd AI Launchpad, die toegang biedt tot LLM’s, maar we wilden dat deze nuttiger zou zijn.
We hebben gekeken naar hoe werknemers AI-tools gebruiken, op basis van onze ervaring en enquêtegegevens. Data-analyse is een veelvoorkomend gebruiksscenario. Maar om te analyseren moeten mensen gegevens downloaden, in een context plakken en een heleboel stappen doorlopen. Onze startmotivatie was dus: hoe maken we die workflows eenvoudiger, handiger en betrouwbaarder?
Rond die tijd was ik op een AI-retraite in Boston en sprak met Romesh Raskar bij MIT over hoe het agentische web eruit zal zien en de noodzaak om er een open versie van te bouwen. Dat weekend kwam al snel in actie. Zaterdag tijdens de retraite, daarna zondag sprekend op MIT, waarbij mensen werden uitgedaagd om betere agentervaringen voor Boston op te bouwen. Vervolgens zeiden we maandag: laten we proberen een MCP-server te bouwen en deze te verbinden met AI Launchpad.
Omdat we briljante studenten hadden, hadden we in oktober een prototype dat verbinding maakte met het open dataportaal. Sinds november en december zijn we bezig geweest om het betrouwbaarder te maken. Het leverde goed werk bij het vinden van datasets, maar was niet zo sterk in het analyseren van grote datasets: goed voor kleine steekproeven, minder goed op schaal.
Eén innovatie was om meer rekenkracht naar het opendataportaal zelf te pushen. De meeste dataportals kunnen query’s uitvoeren. We gebruiken de portal dus om meer analytisch werk te doen, wat de betrouwbaarheid verbetert en de algehele interactie ook efficiënter en kosteneffectiever maakt.
U hebt hier ook over gesproken als een repliceerbare laag van digitale publieke infrastructuur. Wat hebben steden nog meer nodig om dit te kunnen realiseren?
Daarom zijn wij enthousiast. Met de opkomende technologie is het mogelijk dat we over zes maanden een ander acroniem zullen gebruiken, maar op dit moment lijkt MCP een echt pad om dit op te lossen.
Wij zijn van mening dat MCP een onderdeel is van de digitale publieke infrastructuur en gekoppeld moet worden aan de digitale publieke infrastructuur (DPI). Het agentische web is alleen nuttig als het betrouwbare, veilige bemiddeling creëert die echte mensen dient. AI kan helpen als iemand het druk heeft, geen Engels spreekt of een beperking heeft. Er zijn veel redenen waarom dit van belang kan zijn voor de toegang. Maar zonder de juiste infrastructuur wordt de ervaring minder betrouwbaar.
Het MCP-patroon is aantrekkelijk omdat je bestaande DPI-componenten – identiteit, API-exposures, betalings-API’s – kunt benutten door een middenlaag te creëren tussen wat een AI-systeem ‘ziet’ en de onderliggende infrastructuur die de overheid al heeft, op een manier die betrouwbaarder kan worden gemaakt.
We beginnen met open data omdat deze weinig risico’s met zich meebrengen en al openbaar zijn. Maar het zou kunnen evolueren naar bemiddeling rond serviceverzoeken en andere interacties. Wij zijn van mening dat de overheid het vermogen moet hebben om dit op te bouwen en te beheren. Maar we kunnen ons ook voorstellen dat leveranciers dit soort interfaces integreren in de producten die ze aan overheden verkopen.
Laten we het over veiligheid hebben. Welke bedreigingen voelen het meest realistisch aan bij agentsystemen, en hoe helpt MCP?
Eén punt van zorg is dat onze API’s niet altijd goed beveiligd zijn. Er zijn agentische browsers en tools die het eenvoudig maken om interacties te automatiseren. En we zien steeds meer verkeer naar boston.gov dat niet van mensen komt, maar van AI-systemen die ‘diep zoeken’.
Het is niet moeilijk voor te stellen dat AI-tools ook om diensten vragen. Een groot risico ontstaat wanneer een AI-tool verzoeken doet die niet verband houden met een echte menselijke behoefte. Er kunnen frauduleuze verzoeken zijn of actoren die schaarste creëren door beperkte overheidsbronnen te verbruiken en mogelijk toegang door te verkopen, vergelijkbaar met het scalperen van kaartjes bij concerten.
Een ander risico is dat het zonder een gecontroleerde laag moeilijker is om het verkeer tussen AI-systemen en overheidssystemen te beveiligen en te monitoren.
Wat ons enthousiast maakt over MCP-servers is dat deze middleware het gemakkelijker zou kunnen maken om ongeautoriseerde inkomende agentische verzoeken te blokkeren met cyberbeveiligingstools, terwijl legitiem gebruik nog steeds mogelijk is. Het idee is: mensen die diensten nodig hebben, gebruiken een geautoriseerd kanaal dat door de overheid wordt gecontroleerd, kunnen worden geassocieerd met identiteit en kunnen end-to-end monitoren en beveiligen.
Zonder die middleware staat de overheid voor een ongemakkelijke keuze: de interactie tussen agenten volledig blokkeren, of deze open laten. MCP biedt een middenweg: governance voor agentische interacties.
Zijn er dingen waaraan u MCP momenteel opzettelijk niet blootstelt?
We beginnen met open data. Ons AI-beleid in Boston, dat een paar maanden geleden werd uitgerold, stelt dat we AI niet gebruiken om informatie te verwerken die de levens, eigendommen of burgerlijke vrijheden van mensen zou kunnen beïnvloeden vanwege betrouwbaarheidsproblemen en intrinsieke, complexe vooroordelen.
Voorlopig zijn dit dus categorieën die we vermijden. Het is niet alleen ‘een mens die op de hoogte is’. We weten dat AI-intermediatie nadelige effecten kan veroorzaken die moeilijk te detecteren en te verhelpen zijn.
Tegelijkertijd werken we nauw samen met de gehandicaptengemeenschap en met mensen die te maken hebben met taaltoegangsproblemen. De overheid is moeilijk toegankelijk voor mensen die haar het meest nodig hebben. En dat zijn vaak dezelfde mensen die het minst waarschijnlijk privétoegang hebben tot LLM’s, betaalde abonnementen, betrouwbaar internet en persoonlijke apparaten.
Als je een toverstaf zou hebben, wat is dan de grootste blokkering die je zou verwijderen?
Er zijn technische hiaten omdat MCP nieuw is. In het begin ondersteunden MCP-servers sommige authenticatieonderdelen niet standaard; we moesten raamwerken toevoegen om ze te beveiligen. Het ecosysteem verandert snel.
Maar het allerbelangrijkste is vindbaarheid en gebruiksgemak. We moeten op een punt komen waarop het gebruik van de MCP-infrastructuur net zo eenvoudig is als het verwijzen van een LLM naar een URL. Bij websites typt u de naam of gebruikt u de zoekfunctie. Dat hebben we nodig voor MCP: triviale ontdekking, triviale toegang, feitelijk geen toetredingsdrempel. We hebben het eenvoudiger gemaakt, maar er is nog steeds te veel technisch voorwerk.
Wat is de actie die een andere stad die deze kant op wil gaan nu moet ondernemen?
Goed metadatabeheer is essentieel. LLM’s verbruiken gegevens, maar begrijpen niet wat het is zonder goede beschrijvingen en context. Het begint dus met goed databeheer.
Wij zijn van plan dit werk te delen. We zijn er trots op, en dankzij de samenwerking met het GovLab en het Burnes Center hebben we snel tot actie kunnen overgaan. We zijn van plan om van Open Context een open-sourceproject te maken, zodat anderen het kunnen repliceren.
De MCP-server zelf kost niet veel om te draaien. Ons doel is om het zo eenvoudig te maken als het implementeren van een pakket in welke openbare cloud dan ook die een stad gebruikt. De rest van de puzzelHoe dit aansluit bij bredere diensten, is iets dat elke stad zal moeten oplossen, en dat doen we ook in Boston.
Maar belangrijker nog: gegevens worden pas nuttig als mensen ze gebruiken. De datakwaliteit verbeterde toen we open data gingen publiceren. Wij denken dat het bestuur en de kwaliteit verder zullen verbeteren als meer mensen open data gebruiken. En we hopen dat GenAI het voor mensen gemakkelijker maakt om open data te gebruiken, zodat we problemen gezamenlijk kunnen oplossen.
—
Een versie van dit interview werd oorspronkelijk gepubliceerd op Herstart de democratie.



{kind=link}